Basic Data Structure¶
Stack¶
Strategy (Implementing Stack)
For convenience, we can implement a stack using an array:
1 2 3 4 5 6 7 8 9 10 11 | |
Strategy (Opposite Stacks)
Putting two stacks on the opposite direction to simulate Editor-like effect.
Exercise (In/out Stack)
Given \(n\) integers \(1, 2, \cdots, n\), we want every number to be pushed into an infinite stack once and then popped once. If the in-stack order is \(1, 2, \cdots, n\), then how many possible out-stack orders are there?
Solution 1 (Iteration)
Consider the position of \(1\) in the out-stack order. If \(1\) is on position \(k\), then the process is:
1. push \(1\) into the stack
2. push \(2 ~ k\) into the stack and then pop them in some unknown order
3. pop \(1\)
4. push \(k+1 ~ n\) and then pop them in some unknown order
Then we get the iterative formula:
The time complexity is \(\mathcal{O}(n^2)\).
Solution 2 (DP)
Define \(f[i,j]\) be the number of possibility that there are \(i\) elements not pushed and \(j\) elements left in the stack. Under any situation, there are two choices: push an element or pop an element. The Bellman Equation is:
The time complexity is \(\mathcal{O}(n^2)\).
Solution 3 (Math)
This question is equivalent to calculating the nth Catalan number, i.e.
The time complexity is \(\mathcal{O}(n)\).
Definition (Infix, Prefix, Postfix Notation)
Infix Notation: operators are in-between every pair of operands. e.g. \(3 * (1 - 2)\)
Prefix Notation (Polish Notation): operators are before two expressions. e.g. \(* \; 3 - 1 2\)
Postfix Notation (Reverse Polish Notation): operators are after two expressions. e.g. \(1 2 - 3 \; *\)
Important Note (Computing Postfix Expression)
Use a stack. Scan the expression following these steps:
1. if encounter a number, push it into the stack
2. if encounter an operator, pop out two elements from the stack, calculate and push the result into the stack
The time complexity is \(\mathcal{O}(n)\).
Important Note (Computing Infix Expression)
The fastest way to compute an infix expression is to first turn it into a postfix expression. We can do this following these steps:
1. if encounter a number, output it
2. if encounter a (, push it into the stack
3. if encounter a ), pop and output elements until we popped a (
4. if encounter an operator, pop and output elements until the priority of the operator > the element we intend to pop, then push the operator into the stack; The priority ranking is: */ > +- > (.
After scanning all elements in the expression, we pop all the elements from the stack.
The key idea here is to use stack to "wait" for ) if encounter a (, or another number if encouter an operator.
Monotonic Stack¶
Exercise (Largest Rectangle in a Histogram)
Find the maximum area of the rectangle that can be outlined in a histogram.
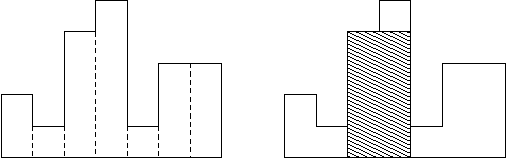
Solution
Consider if the each small rectangle in the histogram is increasing height, then we can simply enumerate heights and ignore all the rectangle on the left for a certain height. When a shorter rectangle comes, we can first view all previous rectangles as increasing height histogram, and then ignore the heights that are larger than the new shorter rectangle. In other word, we are maintaining a Monotonic Stack. To implement this, we add a rectangle of height 0 at the end to activate final pop.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
This is the famous monotonic stack, with time complexity \(\mathcal{O}(N)\). The key idea here is to erase impossible choices and maintain the set to be effective and in order.
Queue¶
Strategy (Implementing Queue)
For convenience, we can implement a queue using an array. Actually, this is a deque. Note that we cannot push_front using array. Better try STL deque.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Monotonic Queue¶
Exercise (Maximal Interval Sum)
Given a sequence of \(n\) integers, find a consecutive interval within length \(m\) (at least one) that has the maximal sum. Note that there may be negative numbers.
Solution
We use prefix sum to calculate interval sum. Then, we enumerate right endpoint, which is equivalent to sliding a window of length \(m\). Now the tricky part is how to quickly find the left endpoint in that window.
Given a right endpoint \(i\), consider two position \(j\) and \(k\): if \(k<j<i\) and \(S[k] \ge S[j]\), then for all right endpoints on the right side of i, k will never be the solution. This is because \(k\) is farther away from \(i\) and \(k\) is worse than \(k\), so \(k\) will no longer be a choice for all right endpoitns on the right side of \(i\). We can simply maintain a monotonic queue to keep record of current possible choices for left endpoints. We use a deque to store positions, and array s to store prefix sum. Detailed steps are:
1. if the deque stores elements more than \(m\) away from \(i\), pop from the front
2. update answer, s[i] - s[q[l]] is the maximal sum when i is the right endpoint
3. pop the elements from the end until the end is less than s[i](maintaining monotonic queue)
4. push i

1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
The order of these operations? The logistic is:
1. When we settle a new i, before we update the answer, we must first clean the outdated choices
2. We can update our data because the queue is maintained to be monotonic
3. After we put i into the queue, we must maintain a monotonic queue
Note that there should be at least one element in the queue, or we cannot ensure there is at least one element in the queue. Thus, it is vital important to put q[++r] = i; at the end of the loop. The right endpoint we are considering at the begining of the loop is \(i\), and notice that \(i-1\) will always be in the queue as it is push into the queue at last without popping, which guaranteed that we have at least one element in the interval (in the queue).
Linked List¶
Strategy (Implementing Linked List)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
Note (Advantage of Linked List)
The key advantage of linked list is that it allows us to insert or remove elements between elements in \(\mathcal{O}(1)\).
Exercise (Neighbor Value Search)
Given a sequence \(A\) of length \(n\), for each element in the sequence \(A_i\), find:
and corresponding \(j\). If multiple minimum exist, pick smaller \(A_j\).
Solution
Note that the answer for \(A_i\) only depends on \(A_1, \cdots, A_{i-1}\), so we can process the sequence from the back to the front, deleting already processed elements using linked list. More precisely, sort \(A\) and construct a linked list for the sorted elements. Use array B to record the index of the original sequence, i.e., \(B_i\) (a pointer) points to the element \(x\) in the linked list, where \(x\) is indexed \(i\) in \(A\). Then, for each \(A_i\), the prev and next in the linked list are the closest elements we need to compare. We process \(B_n\), and then delete the element \(B_n\) points to; and then we process \(B_{n-1}\), delete the element \(B_{n-1}\) points to, and so on...
Exercise (Running Median)
See ...
Adjacency List¶
It is said that adjacency list and forward star representation are different in a way that adjacency list uses linked list and forward star uses array, but they share the same idea. In OI, I'll just use forward star.
Definition (Forward Star)
1 2 3 4 5 6 7 8 9 10 11 | |